
Matt Neuburg is the author of REALbasic: The Definitive Guide, and a member of the editorial board of REALbasic Developer. This article was originally published in REALbasic Developer Issue 1.4 (Feb/March 2003).
Here’s a problem that arises frequently in computing: You’re going to be handed a lot of items of data, and then shown a new item and asked whether you’ve already been handed one identical to it, and if so, where you put it.This is a problem that arises in real life, and we can use real-life reasoning to analyze it. Suppose, for example, that you are a doctor with two or three hundred patients. You’ve got a file of information on each patient; when a patient comes in for an appointment, you’d like to lay your hands on that patient’s file. How do you store the files?
You could just have a room where all the files are thrown helter-skelter on the floor; but this would not be very efficient. It guarantees that all the files are in one place, but you might have to examine every single file in order to find the one you want. A better answer is, of course, a filing cabinet. For purposes of discussion, let’s imagine a filing cabinet with 26 drawers. If each drawer is labelled with a letter of the alphabet, in order, then we could use the first letter of a patient’s last name to tell us where to put that patient’s file — and where to find it again later. Instead of a big room containing all the files, we’ve now got 26 little rooms, each containing just a few files.
A filing cabinet is a real-life example of hashing. Hashing is the algorithmic equivalent of the old saying, “A place for everything, and everything in its place.” Hashing depends on two things. First, we must have a set of little rooms. Instead of the drawers of a filing cabinet, you might like to think of these rooms as pigeonholes, as in one of those old-fashioned desks you may have seen in an antique shop. In the computer world, these pigeonholes are likely to be the elements of an array, because each element is labelled, and can be accessed directly, through its index number. Second, we must have a rule for placing each piece of data in its pigeonhole, and for finding it there again later. This rule must depend on something about the data itself, and is called the hash function. By applying the hash function to a piece of data, we obtain a hash key which specifies the correct pigeonhole. If the pigeonholes are elements of an array, the hash key will need to be an integer within that array’s bounds.
In the computer world, just as in the real world, the big questions are how many pigeonholes we’ll need and what the hash function will be. For a few hundred patients, our 26-drawer filing cabinet and our hash function using the first letter of each patient’s last name are likely to prove adequate. But, for example, when James Murray took over the work of editing the Oxford English Dictionary, he needed a room with over a thousand pigeonholes. In general, more is better (up to the point where storage becomes problematic, as it did for Murray), provided the hash function distributes typical data fairly evenly over the pigeonholes.
A related problem is what to do with multiple items that end up in the same pigeonhole (technically known as “collisions”). If these are many, we might consider maintaining them in some fixed arrangement, as when we order within a drawer the files of two patients whose last names begin with the same letter, by looking at the second letter. Surprisingly, however, if our hashing function is good, this is usually not necessary; in fact, it’s likely to be more trouble than it’s worth. After all, in real life if we had just five or ten files per drawer in our filing cabinet we might not bother to alphabetize them, since we can “just see” the file we want; and a computer is so fast and accurate that it can scan through an ordered clump of, say, several dozen items and “just see” the right one. Thus, a perfectly good way of dealing with collisions might be to store them as a linked list, in whatever order they arrive. (Linked lists were the subject of this column in the August/September 2002 REALbasic Developer.) To learn whether an item is present already in a pigeonhole might require traversing its entire list, but the penalty will be negligible if the list is reasonably small.
Figure 1 illustrates such an implementation. The item “time” is just in the process of arriving. The hash function, represented by the inverted triangle, is assigning it to pigeonhole T; from there we traverse the list, discover that “time” is not already present, and append it to the end of the list.
|
| Figure 1: Hash pigeonholes consisting of linked lists |
To illustrate, let’s set ourselves a practical problem. We will count the occurrences of every word in a text file (thus constructing what is known as a “histogram”). Instead of using as our hash function the first letter of each word, we’ll do something slightly more sophisticated, though not much more: we’ll get the numeric values of the first and last letters of each word and multiply them. Since a character’s numeric value could in theory range from 0 to 255, we’ll need at most 65536 pigeonholes, which we’ll represent as an array.
Each datum will be a string (the word being counted) and an integer (the count of how many times that word has occurred so far). This calls for a class, which we’ll name StringAndInteger, with a property s as string and a property i as integer. To implement linked lists of these, we’ll also give StringAndInteger a property nextOne as StringAndInteger. Our array, which we’ll call hashTable, will thus be declared as an array of StringAndInteger, of size 65536. Before we start, we initialize every element of this array to a new empty StringAndInteger — that is, by auto-initialization, one whose s is the empty string, whose i is 0, and whose nextOne is nil.
Here, then, is our hash function, which transforms a string into a number by multiplying its first and last character values:
SimpleHashValue:
Function simpleHashValue(word as string) As integer dim startasc, endasc as integer startasc = asc(mid(word,1,1)) endasc = asc(mid(word,len(word),1)) return (startasc*endasc) End Function
As each word arrives, we hash it to get the appropriate index of the hashTable array. At that index is the head of a linked list, which we traverse looking for the same word, until we hit the end of the list. If the end of the list isn’t a new empty StringAndInteger, we append one. Having reached either our word or an empty StringAndInteger, we stop, put our word there, and increment i.
Store:
Sub store(word as string)
dim si as stringAndInteger
si = hashtable(simpleHashValue(word))
while (si.s <> "" and si.s <> word)
if si.nextOne = nil then
si.nextOne = new stringAndInteger
end
si = si.nextOne
wend
si.s = word
si.i = si.i + 1 // count
End Sub
That’s really all there is to it. However, it is of interest to know how good our hash function turned out to be. I used as my test case a text file about 20,000 words long, consisting, as it turned out, of about 4000 distinct words. Using SimpleHashValue as the hash function, these 4000 words ended up in just 300 of the 65536 pigeonholes. That’s not very good, but there is worse news to come: their distribution was tremendously uneven, as the scatter-chart in Figure 2 shows. 57 of the pigeonholes held just one word each (at the right of the chart), but at the other extreme (the left of the chart), one pigeonhole held 83 words, one held 85 words, and one held as many as 103 words!
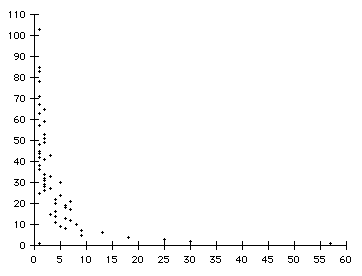 |
| Figure 2: A depressingly bad distribution of data into pigeonholes |
We can achieve much better hashing performance by turning to the pros for help. Here is a highly sophisticated hash function by the computer scientist Peter J. Weinberger:
SmartHashValue
Function hashValue(s as string) As integer
declare function BitShift lib "CarbonLib"
(value as integer, count as integer) as integer
// negative count means to the right
declare function BitAnd lib "CarbonLib"
(value as integer, value2 as integer) as integer
declare function BitXor lib "CarbonLib"
(value as integer, value2 as integer) as integer
dim i,u,hashValue,temp as integer
u = lenb(s)
for i = 1 to u
hashValue = BitShift(hashValue,2)+ascb(midb(s,i,1))
temp = BitAnd(hashValue, &hC000)
if temp <> 0 then
hashValue = BitAnd(&h3FFF,BitXor(hashValue,BitShift(temp,-12)))
end
next
return hashValue
End Function
Using the same test case, this distributes the 4000 distinct words into nearly 3500 pigeonholes in an extremely even fashion, with just one or two words in most pigeonholes, and no pigeonhole containing more than 4 words.
When it comes to speed, however, it turned out in my testing that it didn’t really make much difference which hash function I used; the time required to parse the whole text file using the first hash function was about 17 seconds, compared to about 16 seconds using the second hash function — a negligible difference. The reason is simple. The actual hashing times really are significantly different: about 2.1 seconds for my simple hash function, about 1.2 seconds for Peter Weinberger’s hash function — mine is almost twice as slow. But these differences were overwhelmed by the activity in which my program turned out to be spending most of its time, namely, breaking the text file into individual words! The moral of the story is that there’s no point optimizing until you know what needs optimization. Unless I can make the process of breaking the file into words much faster, my simple hash function will do perfectly well.
It’s important also to understand that, in REALbasic, there is really no need to implement our own hashing at all. Just as we saw in the Linked Lists column that all the necessary linked-list functionality is already built into REALbasic arrays, so there’s already a hashing class built into REALbasic — the Dictionary class. To finish up, then, here’s how to implement Store using a Dictionary.
Store (the Dictionary version):
Sub store(word as string)
dim ct as integer
if dict.hasKey(word) then
ct = dict.value(word)
ct = ct + 1
dict.value(word) = ct
else
dict.value(word) = 1
end
End Sub
This does the hashing in about 0.6 seconds, twice as fast as my REALbasic implementation of the Weinberger hash function. So in real life you’d probably use the Dictionary class for all your hashing needs. Nevertheless, we’ve learned something important: we know what hashing is, and we can now envision how the Dictionary class really works, behind the scenes. In general, key-value storage of all kinds, as in a Dictionary, depends upon hashing; another example is a compiler, which uses hashing in many ways, such as keeping track of the variable names at each level of scope.